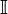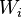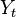원문: http://warpproject.org/trac/wiki/Exercises/13_4/IntroToSDK
Introduction to the Xilinx Software Development Kit (SDK)
(compatible with WARP v3)
In this exercise, users will be introduced to a tool that is used heavily in WARP development: the Xilinx Software Development Kit (SDK). Users will use these tools to construct a simple "Hello World" software project that prints messages via UART to a terminal running on the user's PC and controls the User I/O on the board to run on and off LEDs and display numbers on the hexadecimal displays.
유저는 SDK를 사용하여서 (간단한 example 을 구현한다.) 헬로월드 따위를 PC로 전송하여 터미널에 디스플레이 할 수 있고 몇가지 I/O 포트 제어 및 LED 제어가 가능할 것이다. SDK는 이클립스의 IDE와 유사하며, 그리고 주로 사용하는 언어는 C와 C++ 이다. 이를 통하여 마이크로 블레이즈 CPU를 제어한다.
The SDK will look very familiar to users who are comfortable with the Eclipse IDE. Basically, the SDK allows users to write custom C or C++ code to execute on the MicroBlaze processor. Furthermore, it natively supports step-by-step debugging of code as well as code profiling.
Prerequisites
필요한 준비물은 아래와 같다. PC와 연결한 와프 보드와 인터페이스 JTAG이 필요하다. +정전기 방지에 대한 숙지.
보드만 구매하면 낭패를 볼수있으니, 반드시 호환되는 JTAG 케이블도 함께 구매하길 바란다.
- You have a WARP v3 board
- ESD protection for the WARP board (wrist strap, etc)
- External USB JTAG cable and a micro USB cable for UART
- Complete installation of ISE System Edition 13.4
- Set up a terminal on your computer using PuTTY or an alternative. Instructions to do this are available instructions here.
Instructions
매우 간단한 예제를 따라하면서, 새프로젝트의 생성 및 디버거 툴을 사용해보면서 익숙해지는 과정을 상세히 설명하고 있습니다. 주석이 필요한 부분만 달고 나머지 부분은 직접 따라해보길 권장합니다.
- Download the WARP v3 Template Project. Note: any template for your version of the hardware will work fine for this exercise as only the SDK is necessary. In general, when FPGA hardware designs must be generated, the "lite" template will build the quickest, but it lacks peripherals like Ethernet that may be necessary for designs other than this simple Introduction to the SDK exercise.
앞서 이야기한 예제를 실행하기 위해서, 위의 링크의 프로젝트를 다운로드 합니다. 이는 섹션4의 마지막 파트에서 설명하게되는 프로젝트 예시파일과 같습니다. (* Template Projects) 실행을 위해서는 SDK가 반드시 필요합니다. 일단적으로 FPGA 하드웨어 디자인들이 생성될때, lite 버전의 템플릿들은 빠르게 생성되지만 그것은 이더넷과 같은 주변장치를 제외하기 때문에 초기 학습에 적합하지 않습니다. - Extract the archive into a folder on your hard drive. Note: this folder must not contain any spaces in the path (this includes folders such as "My Documents" in Windows; Please note that in Windows 7, the Desktop folder can be used, "C:\Users\<username>\Desktop", whereas in previous versions of Windows the Desktop folder was under the "Documents and Settings" directory and could not be used).
어쨌거나 템플릿 프로젝트 파일의 압축을 풀고, 해당폴더는 최상위 폴더여야 합니다. - Launch the Xilinx SDK from the Start Menu. It will ask you to select a workspace. Click "Browse ..." and navigate to the "SDK_workspace" folder in the archive you just extracted. Do not check the box for "Use this as the default and do not ask again." We recommend the convention of using a single workspace per hardware project; checking this box will make this difficult. More useful tips for using the SDK are available here. Click OK.
시작메뉴의 자일링스 SDK를 실행시킨다. SDK작업폴더로 이동한다. default 설정을 유지한다. 이 옵션을 선택하지 않으면 귀찮아 진다. 더 많은 정보는 here 링크를 참조하세요. - Rather strangely, the Xilinx SDK does not automatically know about software drivers to custom peripherals in your XPS project. You have to explicitly tell the SDK where to find your hardware project. This is a step you have to do with every new SDK workspace. In this exercise, we do not have any custom peripherals, but it is still a good habit to get into. Click on the "Xilinx Tools" menu item and select "Repositories." Here, you want to ensure two things:
- In Local Repositories, you want to point the SDK to the folder that contains the XPS project system.xmp file. Click on "New..." and navigate to and select this folder.
- In Global Repositories, you want the SDK to point to the edk_user_repository folder on your hard drive. Unlike the local repositories, the SDK does remember this setting across workspaces. You'll only need to manually add the edk_user_repository the first time you run the SDK.
자일링스 SDK는 자동적으로 소프트웨어 드라이버를 찾거나 알지 못합니다. 따라서 당신이 명확하게 지정해주어야 합니다. 이는 새로운 SDK workspace를 생성할때마다 반복해야 합니다. 실질적인 SDK와 XPS의 사용법은 직접 실행을 통하여 익숙해지길 권합니다.
- In the template project you downloaded, we have provided a template software project. We now need to add it to the workspace. Click on File→Import...
다운로드한 템플릿 프로젝트는 현재의 작업영엑 추가해야한다. 클릭후 파일메뉴에서 불러오기 선택.
(이제부터 아래의 메뉴얼의 내용대로 진행하세요. 앞으로 추가설명이 필요한 부분만 주석처리 하겠습니다.) - Click the + next to "General" and select "Existing Projects into Workspace." Then click "Next."
- In the "Select root directory:" click "Browse..." Then, navigate to the "SDK_workspace" folder in the extracted archive and click "OK"
- Three projects have now been populated in the "Projects" area of the import window. Make sure all of these are checked. Do not check "Copy projects into workspace" because these projects are already in the SDK_workspace folder. Click "Finish."
- The three projects now appear in the "Project Explorer" on the left of the screen:
세개의 프로젝트에 대한 정보를 이름과 관련된 파일들로 분류하여 설명합니다.- The "*_hw_platform" contains all of the necessary hardware-specific information for the project. This includes any custom FPGA cores that the project may have. This comes from the Xilinx Platform Studio (XPS) tool. Instructions for using this tool to generate hardware platform information for the SDK is available in the Introduction to XPS exercise.
- The "*_bsp" is a "Board Support Package" and it contains the software drivers for the peripherals contained in the hardware platform.
- The "*_example" project is the top-level software project that you will modify to add a print of "Hello World" to the UART.
- Click the + button next to the "*_example" project. Then open the "src" folder by clicking the + button next to it. Finally, double click the "*_example.c" file to open it in the editor. At this point, you can look through this source code and see that it will print some messages to the terminal and will count upwards, displaying the current count on the hexadecimal displays on the WARP board and the LEDs.
- Right click on the "*_example" software project in the Project Explorer and click "Generate Linker Script." Here, we will assign instruction and data pieces of our code to various pieces of memory in our XPS hardware project. Assign the following:
- The code sections to "ilmb_cntrl_dlmb_cntlr"
- The data sections to "xps_bram_if_cntlr_0"
- The heap and stack to "xps_bram_if_cntlr_1"
- Click "Generate" and then "Yes" to the message that says you are going to overwrite an existing linker script. The console will print messages and end with "Finished building: *_example.elf.elfcheck"
- Make sure your WARP hardware is powered on (fan should be running). Also make sure the WARP hardware is connected via JTAG (for programming) and connected via micro USB (for terminal communication) to your computer.
- Click the "Xilinx Tools" menu item and then "Program FPGA." Then click Program. This will load the hardware design onto the board. It will not load the software project.
- Open up a terminal emulator on your computer and configure it to accept your COM port with speed 57600 baud.
- The SDK is somewhat sensitive on what project has "focus" when you tell it to do something like load a design onto the board. Make sure the "*_example" project is highlighted. If it is not, click on it so that it will be.
- Click the menu item "Run" and then click "Run." A window will pop up asking you to select a way to run your "*_example" program. Click "Launch on Hardware" and then okay.
- The project is now running! You should see the LEDs and hexadecimal displays on the board incrementing twice a second. Furthermore, your terminal should be printing.
- Try to modify any of the prints in the code with your own custom strings. Click save. The SDK will automatically recompile the project. Download it again through the "run" menu.
- Also, find the usleep(250000) line inside the userio_example() function. This line is telling the processor to wait for half a second before incrementing the displays upwards. Replace this with usleep(500000) and you should see the board count half as fast.
Discussion
The purpose of this exercise was to take you through the whole process of writing software for an existing hardware project. In the System Generator Peripheral Export exercise, you will develop a custom FPGA peripheral core and control it via custom software.
Additional Questions and Feedback
If you have any additional questions about this exercise or other feedback, please post to the WARP Forums.
'N.&C. > WARP v3' 카테고리의 다른 글
| 3-2. Introduction to the Xilinx Platform Studio (XPS) (0) | 2016.05.03 |
|---|---|
| 3-1-2. WARP v3 User Guide: Template Projects (0) | 2016.05.03 |
| 3. Getting Started with the Xilinx tools (0) | 2016.05.03 |
| 2. Recommended Tools and Equipment (0) | 2016.05.02 |
| 1. Getting to Know the Hardware (0) | 2016.05.02 |


















![0 < \mathbb{E}[S_i] < \infty.](http://upload.wikimedia.org/math/6/4/2/642646acd87e01cd6befabcb8ba03731.png)
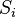

![\mathbb{E}[S_i]](http://upload.wikimedia.org/math/9/2/e/92e2d7bbd26c3eb3dfb9666dad1b61a3.png)
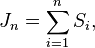


![[J_n,J_{n+1}]](http://upload.wikimedia.org/math/6/b/e/6bec9ae0b54f0d735f3511a0aa7f0507.png)