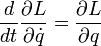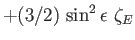A Markov model is given visual representation with a state diagram, such as the one below.
State Diagram for a Markov Model
The rectangles in the diagram represent the possible states of the process you are trying to model, and the arrows represent transitions between states. The label on each arrow represents the probability of that transition. At each step of the process, the model may generate an output, or emission, depending on which state it is in, and then make a transition to another state. An important characteristic of Markov models is that the next state depends only on the current state, and not on the history of transitions that lead to the current state.
For example, for a sequence of coin tosses the two states are heads and tails. The most recent coin toss determines the current state of the model and each subsequent toss determines the transition to the next state. If the coin is fair, the transition probabilities are all 1/2. The emission might simply be the current state. In more complicated models, random processes at each state will generate emissions. You could, for example, roll a die to determine the emission at any step.
Markov chains are mathematical descriptions of Markov models with a discrete set of states. Markov chains are characterized by:
A set of states {1, 2, ..., M}
An M-by-Mtransition matrixT whose i,j entry is the probability of a transition from state i to state j. The sum of the entries in each row of T must be 1, because this is the sum of the probabilities of making a transition from a given state to each of the other states.
A set of possible outputs, or emissions, {s1, s2, ... , sN}. By default, the set of emissions is {1, 2, ... , N}, where N is the number of possible emissions, but you can choose a different set of numbers or symbols.
An M-by-Nemission matrixE whose i,k entry gives the probability of emitting symbol sk given that the model is in state i.
Markov chains begin in an initial statei0 at step 0. The chain then transitions to state i1 with probability T1i1, and emits an output sk1 with probability Ei1k1. Consequently, the probability of observing the sequence of states i1i2...ir and the sequence of emissions sk1sk2...skr in the first r steps, is
The Poisson process is one of the most important random processes in probability theory. It is widely used to model random "points" in time and space, such as the times of radioactive emissions, the arrival times of customers at a service center, and the positions of flaws in a piece of material. Several important probability distributions arise naturally from the Poisson process--the Poisson distribution, the exponential distribution, and the gamma distribution. The process has a beautiful mathematical structure, and is used as a foundation for building a number of other, more complicated random processes.
* This is not a class material for commercial purpose. It's free for student.*
본 포스팅은 Pure Aloha를 먼저설명하고, Slotted Aloha를 유도한다.
1. ALOHA란?
Random access method의 한 방법으로 1970년대에 제안되었으며 여전히 셀룰러 시스템에서 그 Simplicity를 장점으로 사용된다. assumption
알로하(ALOHA)는 하와이 대학에서 개발되었으며 시분할 다중접속 기술을 사용해 위성과 지구 사이의 무선 전송을 하는 프로토콜이다. 원래의 알로하에서 사용자는 언제든지 전송할 수 있지만, 다른 사용자들의 메시지는 충돌할 위험이 있다. 패킷이 준비되면 브로드캐스트되며, 만약 충돌이 일어나면 일정시간 후에 재전송된다. Slotted Aloha는 채널을 시간대별로 나누어서 충돌 위험을 줄이는 것으로, 각 사용자는 시간대의 시작에서만 전송이 가능하다.
2. Basic working
- 노드는 데이터 전송을 언제든지 할수있고 ACK를 받는다
- 만약 하나의 Frame 이상이 같은 시간에 전송된다면, 그들은 서로 간섭을 겪기때문에 충돌하거나 패킷을 잃어버린다.
(Collision or Lost)
- 만약 ACK 패킷이 지정된 시간안에 도착하지 않으면 Timeout이 발생하고 전송을 한 노도는 Backoff time만큼 기다린후
다시 전송을 시도한다.
2-2. Vulnerable period
- Frame의 길이 (전송할 패킷의 사이즈)를 L이라고 둔다면, L 길이 패킷을 전송하는 소요시간은 X = L/R (data rate)이 됨.
- consider a frame with starting transmission time to the frame will be successfully transmitted if no other frame
collides with it.
-> any transmission that begins in interval [t0, t0+X], or in the prior X seconds leads to collision
vulnerable period = [ t0 – X, t0+ X ]
위의 그림은 Unslotted Aloha의 취약구간을 보여준다. L길이 만큼의 패킷이 전송될 동안 앞뒤로 2L길이만큼 다른 노드들의 전송시도가 없어야만 성공적인 전송이 가능하다.
3. Throughput =(def. Number of packets per unit time)
1) Successful throughput : X시간(unit time) 동안의 성공적인 Frame 전송의 평균값을 의미한다.
2) G-load : X시간 동안의 평균적인 전송시도를 의미한다.
(큰 개념은 굵은 제목들만 봐도 충분히 이해가 된다. 하지만 이를 직접 Code로 구현하기 위해서는 아래의 확률과정에 대해서 충분히 이해해야 한다. G의 개념과 Qa, Qr의 개념만 안다면 코딩가능하다. 필요없는 분은 바로 3)으로 가세요)
"G" refer to the mean used in the Poisson distribution over transmission-attempts that is, on average, there are G transmission-attempts per frame-time in state n.
State (n) of system is number of backlogged nodes.
If a transmission has a collision, node becomes backlogged
– While backlogged, transmit in each slot with probability qr until successful.
Infinite nodes where each arriving packet arrives at a new node
– Equivalent to no buffering at a node (queue size = 1)
– Pessimistic assumption gives a lower bound on Aloha performance
G(n) = λ + n*Qr
( Qr : re-transmission probability of backlogged stations. )
The number of attempted packets per slot in state n is approximately a Poisson random variable of mean g(n)
– P (m attempts) = {(G(n)^k)*exp^-G(n)}/m!
– P (idle) = probability of no attempts in a slot = exp^-G(n)
– p (success) = probability of one attempt in a slot = G(n)*exp^-G(n)
: idel한 채널상태에서 혼자서 전송을 시도하는 경우 = 성공확률.
– P (collision) = P (two or more attempts) = 1 - P(idle) - P(success)
For any frame-time, the probability of there being k transmission-attempts during that frame-time is:
{(G^k)*e^(-G)} / k!
If throughput is represented by S, under all load, S = G*Ps, where Ps is the probability that the frame does not suffer collision. A frame does not have collision if no frame are send during the frame time. Thus, in t time Ps=exp^-G.
In pure Aloha, Ps=exp^(-2G), as mean number of frames generated in 2t is 2G. From the above, throughput in pure Aloha S = G*exp^-2G.
*혼잣말: G= a node transmission-attempts , k= k nodes라면.. 2)과 3)의 설명에서 G와 k의 연결고리가 없는 느낌인데..
3) Successful Probability (Ps): 성공적인 Frame전송의 확률
따라서 Successful throughput = Ps * G-load.가 된다.
if general, if frame arrivals are equally likely at any instant in time, and arrivals occur at an average rate of λ [arrivals per sec]
포아송 프로세스를 따라서 동일 프레임들K개가 T시간동안에 도착한다고 가정한다면, 위의 식으로 표현된다.
in our case, λ=G/X [arrivals per second] and T=2X, hence
그러나 앞서 이야기했듯이 Pure Aloha는 프레임길이의 2배동안 다른 노드들의 프레임전송이 없어야 충돌이 없기 때문에 전송이 성공하기 위한 조건들을 대입하면 아래와 같이 다시 쓸수가 있다.
accordingly, probability of successful transmission (no collision) is:
이를 푸아송 프로세스의 성질을 이용하여, 어떠한 전송이 없을 확률을 구하면 = 다른 노드들이 모두 전송하지 않을 확률 = 성공확률을 의미한다.
따라서 Throughput 은 평균적인 전송시도량 * 패킷전송 성공확률로 표현이 된다.
4. Slotted Aloha
Slotted Aloha는 pure Aloha보다 향상된 성능을 가지는데, 이는 충돌량이 감소했기 때문이다.
1) Assumption
- 각각의 슬롯사이즈들은 X=L/R 의 크기로 나눠어 진다. (하나의 프레임전송에 맞는 시간)
- 노드들은 전송을 슬롯의 시작부분에만 시작한다.
- 노드들은 동기화를 통해서 슬롯의 시작을 알고있다고 가정한다.
2) Operation
(1) when node has a fresh frame to send, it waits until next frame slot and transmits
(2) if there is a collision, node retransmits the frame after a backoff-time
(backoff-time = multiples of time-frames)
위의 그림을 보면 왜 Slotted Aloha가 더 좋은 성능을 가지는지 알수있다. 사실 직관적으로 2배정도의 성능을 보일것이라고 생각이 든다.
3) Throughput
packet P will be transmitted successfully if no other packet becomes available for transmission during the same time slot. Pure Aloha에서 전송시 Vulnerable period가 패킷사이즈(L)의 2배시간동안 다른 노드들의 전송이 있다면 충돌이 발생한다고 했다면, Slotted Aloha의 경우는 Packet Size의 길이만큼만 충돌이 없도록 보장이 되기에 2배의 성능을 보인다.
vulnerable period = [ t0 – X, t0 ]
따라서, Slotted ALOHA와 Pure Aloha 의 성능을 비교해보면 아래와 같다.
Slotted ALOHA의 MAX Throughput 은 G=1일때 0.36을 보인다.
따라서 실질적인 Channel capacity는 36%이다. (legend가 반대로 들어갔습니다. 붉은색 = pure, 파란색이 slotted 입니다. 참고하시길 바랍니다.)
it's a packet stuck in a buffer, unsent to the recipient because of network congestion. You probably don't see the word much in computer networking because it is used in cellular phone networks. In voice networks, where delivery is time sensitive but dropped packets can be tolerated, a backlogged packet is usually dropped.
네트워크분야에서는, 네트워크의 혼잡으로 (CSMA/CA에서 예를들면, 채널이 busy하거나, 패킷간 충돌이 발생했을때) 인하여 전송하려고 하던 패킷을 버퍼에 넣어두고 기다릴 때 전송지연되는 패킷을 말한다.
ex)
In slotted Aloha, If a transmission has a collision, the node become backlogged.
Ways to increase Wi-Fi performance. Part One: Bursting,
Compression,
Fast Frames, Concatenation Read more at
http://ixbtlabs.com/articles2/comm/tech-80211g-super.html#8G5M62mYj7e8urzI.99
Practically all presently manufactured 802.11g wireless adapters have
such suffixes as "super G", "turbo", "plus", etc.
But suffixes are only half the work. Manufacturers (to be more exact, their
marketing specialists) decorate their boxes with the 108 Mbit/s or even
125 Mbit/s labels.
125 - sounds tempting. Can it really be true that wireless
adapters work faster than the good old Fast Ethernet with its cables? Maybe we
should let them go... those "ancient" Fast Ethernet adapters? Get rid
of cables, we are sick and tired of, and long live Radio Ethernet? :)
But look before you leap, as the proverb runs. In our case it
means that it would do no hurt to find out more details about these mysterious
techniques, how they work, and what data rates they really provide (and the
most important thing - under what conditions). In other words, we should make
allowance for the most important thing to marketing guys - to sell solutions
from their company.
There are many ways "to overclock" the standard 802.11g.
To be more exact, every chip manufacturer has its own way (at least - they are
called differently). Unfortunately, not all manufacturers explain the details
of their techniques. I managed to find information on these techniques only forAtherosandTexas Instruments. But the most informative resource is
provided by Atheros - it even has a separateweb
site, devoted to their
Super G and Super AG techniques.
In fact, most part of this article is a compilation of the information
from the web sites of Atheros and Texas Instruments and only minute details
from other sources.
Let's proceed to the techniques.
At first let's have a look at the "pure" 802.11g.
Maximum throughput of this mode is 54 Mbit/s. I guess the majority of
users know how to convert megabits into megabytes? That's right, you should
divide megabits by eight to get the data rate - 6.75 MB/s.
But attentive readers (those who don't just look through
introductions and conclusions, but actually browse diagrams with performance
readings) know that the regular 802.11g mode does not provide more than
~25 Mbit. Hey, that's only half of the 54 Mbit! Where is the other
half? "Where" is a topic in its own right. I can only note that,
indeed, user data makes for only half (at best) of the channel bandwidth.
That's the first bad news. There is also the second bad news.
Radio waves (it's actually them who transmit data in wireless networks) are
transmitted in all directions from the signal source (it's a general case). That
is everyone hears the transmitter. Everyone can choose to receive data or not,
that's not important. What's important - these people cannot transmit anything
on the same frequency at that moment. To be more exact, they can try, but
signals from both sources will overlap, which will lead to the distortion and
loss of the data. In other words, only one of several sources operating at the
same frequency can transmit data at a time in wireless networks. That is the
walkie-talkie principle - first you talk, then you keep silence and listen.
Thus, the generously allocated ~25 Mbit are divided between
all participants of a wireless network. If the number of clients is 5 hosts and
all of them are actively transmitting data, every participant will have the
bandwidth of about 5 Mbit (in fact, it will be even a tad lower).
There is also the third bad news. The second bad news about
5 Mbit per each of 5 hosts is true only in case of Ad Hoc network, that is
without an access point. If we take a more general case with an access point,
those miserable 5 Mbit will have to be divided into two. Any exchange with
clients in the Infrastructure mode (with an access point) goes via an access
point. At first it should receive data and then retranslate it to the
recipient. As a result, we get 2 and a little more megabit per user.
Now let's get back to the figures 108 and 125, which are often
printed in large font on product boxes. But you have already got it, right? :)
Divide these figures by two (we'll touch upon the ideal case later).
That means 60 Mbit maximum in case of one client and consequently n-times
smaller in case of N clients.
If all you want is to find out whether it's time to get rid of
wires or "wait a little", you may skip the rest of the article. The
answer is it's too early so far. At least wait for WiMAX.
Now let's proceed to a more thorough examination of techniques for
increasing wireless throughput compared to the standard 802.11g mode.
I guess all advantages (turbo, etc) of the manufacturers are just
the same thing as in TI and Atheros, but under different names. But
implementation details may be different, so techniques from different
manufacturers may be incompatible with each other.
Atheros technique for 802.11g is called Super G (there is another
one - Super AG; it's the same thing, but for 802.11a, i.e. for 5 GHz
networks). Atheros Super G allows to increase the throughput to
108 Mbit/s. As Atheros honestly declares, user's data rate may reach
60 Mbit.
Performance is increased by several methods:
Atheros Super G / Super AG techniques:
Feature
Characteristics
Benefits
Bursting
more data
frames per given period of time
increase
throughput via overhead reduction
Compression
real-time
hardware data compression
Lempel
Ziv compression
increased
data throughput using precompressed frames
no impact
on host processor
Fast Frames
utilizes
frame aggregation (frame size is up to 3000 bytes) and timing
modifications
increases
throughput by transmitting more data per frame and removing interframe
pauses
Dynamic Turbo
similar
to trunking techniques used in Fast Ethernet networks, utilizes dual
channels to "double" transmission rates
analyzes
environment and adjusts bandwidth utilization accordingly
maximizes
bandwidth using multiple (two) channels
Atheros web site contains a colorful diagram that shows the
influence of various techniques on data transfer rates:
Pic.1, Benefits of various techniques for wireless performance
The base 802.11g or 802.11a mode, where all extended techniques
are disabled, allows up to 22 Mbit (net value, that is available to a
user). Adding techniques, which will probably be included into the future
802.11e standard (Bursting, Fast Frames, Compression), we can increase the
performance up to 40 Mbit inclusive. Activating Dynamic Turbo mode, that
is utilizing dual channels for data transfers, may increase performance to the
theoretical maximum of 60 Mbit.
The above figures are certainly the maximum possible performance
in a given mode (in the ideal case). In reality everything will depend on such
conditions as client's distance from an access point, a number of clients
operating simultaneously, radio environment around the wireless network, etc.
Wireless performance boosts from Texas Instruments are called
G-Plus. Some of them resemble techniques from Atheros, the others are
characteristic of TI alone.
Texas Instruments G-Plus techniques:
Feature
Characteristics
Benefit
Frame Concatenation
merging
data from several packets into one (packet size - up to 4000 bytes)
increases
throughput by removing overheads from "extra" frames and
interframe latencies
Packet Bursting
similar
to the technique from Atheros
similar
to the technique from Atheros
Let's dwell on each of the above mentioned techniques - bursting,
compression, fast frames, dynamic turbo. Interestingly, all the four techniques
work independently, thus maximizing performance simultaneously in several ways.
1. Bursting
Frame Bursting is a transmission technique supported by the draft
802.11e QoS specification. Frame Bursting increases the throughput of any
(point-to-point) 802.11a, b or g link by reducing the overhead associated with
the wireless transmission. This results in the ability to support higher data
throughput in both homogeneous and mixed networks.
Picture 2 shows an example of a standard transmission (without
bursting).
Pic.2, Standard 802.11a/b/g mode
In standard mode we can see the process of transmitting two frames
(frame1 and frame2) from Source to Destination in time. The process of data
transmission is divided into time intervals (axis X is time). As only one
source can transmit data at a time, each station should contend for airtime
during DIFS (Distributed InterFrame Space). If no other station is
transmitting, the airtime is free and a frame can be transmitted. After a frame
is transmitted (frame1), the transmitter waits for a confirmation on a
successful delivery from the destination. The destination must send an
acknowledgement (ack) practically immediately after SIFS - Short InterFrame
Space (if there was no acknowledgement, the source considers that the frame was
not received and must resend it). After receiving an acknowledgement, the
sender must again wait for DIFS and only then (if the air is still free) start
sending Frame 2. And so on.
Thus, DIFS take up a considerable part of wireless throughput.
Now let's see the picture of Frame Bursting transfer:
Pic.3, With Frame Bursting
In this mode (Picture 3), the source and the destination capture a
channel in turns for their transmissions. After frame1 is transmitted and the
acknowledgement is received, the transmitter does not wait the required DIFS.
The sender waits only SIFS and then transmits the second data frame, etc. Thus,
the sender does not give an opportunity for other stations to start
transmissions - they have to wait for the end of this burst transmission.
Of course, the total transmission time in this mode is limited
(otherwise, transmission of several gigabytes would have paralyzed other
clients of a given wireless network completely). But eliminating DIFS allows a
larger chunk of data transmitted over the same period of time, thus saving the
channel throughput, that is increasing the total transmission performance.
Atheros announces that all its products support this technique.
But devices from other manufacturers, which do not support this technique, may
fail to understand this burst mode. So, if communicating with a product that
fails to acknowledge a burst transmission, the source falls back to the base
mode.
Implementation of Bursting from TI is similar to Atheros. TI
provides the following illustration of its technique (Picture 4):
Pic.4, Frame Bursting from Texas Instruments
TI also eliminates the "long" interframe space, by
reducing overheads on transmission.
Both companies do not provide information on compatibility of
burst techniques from TI and Atheros.
Similar "bursting" techniques are probably offered by
other manufacturers as well. But Atheros went further than that and expanded
this technique to "dynamic bursting". It announces that this
technique is especially effective in networks with the number of wireless
clients exceeding one.
For example, if there are two stations, near and far from an
access point. Of course, the far station will operate with an access point at a
lower data rate (because of the distance). That's why its transmission (to the
near client) of a given size will take more time than it will take the near
client to receive the data. In this case bursting activation for the far
station allows to reduce the airtime and, strange as it may seem, it also
allows the nearby station to receive this data still faster (since it will
spend less time contending for airtime). Burst transmission periods also depend
on the distance (to be more exact, on data rates). The nearby client is granted
a longer burst transmission, as it will burst more frames, while consuming much
less airtime.
Atheros Compression technique
The second technique from Atheros that extends the 802.11 standard
is hardware compression. It's built into all 802.11a,b,g chipsets from this
company. It uses the Lempel Ziv algorithm. The same algorithm is used in such
archivers as gzip, pkzip, winzip. This engine compresses prior to transmission
and decompresses after reception.
Unfortunately, the data is not analyzed before it's compressed,
all frames are compressed. Thus, it's not always good - for example, sending an
already compressed file may increase the size of wireless transmission.
On the other hand, well compressible data will be transmitted in
smaller frames, thus consuming less airtime. This airtime can be used by other
wireless stations.
Atheros Fast Frames
Fast Frames technique bundles two frames into a single larger
frame. Thus we eliminate extra overheads (in the header of the second packet -
there is only one header in the new packet left) and interframe spaces:
Pic.5, Regular Transmission
Pic.6, with Fast Frames
The size of the resulting frame may reach 3000 bytes, which is
twice as large as the maximum frame size of a standard ethernet packet. Thus,
Fast Frames technique will work even with wireline transmissions with maximum
packet size (1500 bytes), by merging each two ethernet packets into a single
larger packet. Once FastFrames have been negotiated between an access point and
a station, both the AP and the station can send wireless frames of 3000 bytes
to the corresponding peer.
Considering that Fast Frames can operate together with Frame
Bursting, we get very good data rates. By the way, according to Atheros, most
manufacturers, using Frame Bursting in their chips, actually don't support Fast
Frames. Atheros is all right - their devices support both techniques.
The Fast Frames technique is also based on the 802.11e draft
standard. Nevertheless, it may not be supported by all third party hardware. On
the other hand, this technique functions within existing timing parameters
(unlike Frame Bursting, which exclusively captures a channel for some time).
That's the reason Fast Frames are better for wireless networks that use
equipment from various manufacturers.
Texas Instruments Frame
Concatenation
The Frame Concatenation technique in devices from Texas
Instruments uses the same principles as Fast Frames from Atheros.
TI goes further than that. In this case two or more frames are
merged (Picture 7):
Pic.7, Frame Concatenation
Thus, it gains by eliminating overheads and interframe spaces from
one or more frames. TI claims that its Frame Concatenation technique will work
with any 802.11b/b+/g devices from TI and (!)other manufacturers. It's not
quite clear what this company meant by other manufacturers, if the latter don't
support this technique... Perhaps it meant operations with frames that don't
exceed the standard size (1500 bytes).
Frame Concatenation incorporates an algorithm that allows to merge
only selected packets into mega-frames. For example, if there is only one frame
in queue to be sent to a given destination, it will be sent immediately. In
other words, only frames to the same destination address (MAC address of a
receiver, in this case) will be merged. The algorithm works only with unicast
packets - multicast packets as well as control packets are sent without
changes.
At present, the maximum size of a Concatenation packet may reach
4096 bytes (which is an indirect sign that this technique is not compatible
with its Atheros counterpart).
Conclusion
As we can see, manufacturers are not waiting for the official
announcement of the standards (802.11e in this case), but integrate these new
techniques into their products. Thus, they obtain good results as far as
performance gains are concerned, on the one hand. But on the other hand,
techniques from different manufacturers are often incompatible with each other.
We haven't reviewed Dynamic Turbo from Atheros yet. It will be
described in the second part of the article.
If we find documentation about such techniques as super/plus/etc
from other manufacturers of wireless solutions (or if you post links to such
documents in our forum (the link to our forum is right after this article, a
tad below)), reviews of these techniques will also be added to the second part
of the article.
Read more at http://ixbtlabs.com/articles2/comm/tech-80211g-super.html#8G5M62mYj7e8urzI.99
결론: Wi-Fi에서 Burst mode를 사용하는 모듈(Atheros,TI..)을 구매하여 사용해야 하며, 이는 Burst mode 모듈이 Backoff를 수행하지 않고 SIFS만큼만 대기후 연속적으로 데이터를 전송하기 때문에, 다른 기기들의 채널접근을 막는다. 따라서, 단기간만 Throughput을 올리는 목적으로 사용해야한다.
What is the meaning of the Intended and Offered Load, Forwarding Rate?
I provide explanation of difference between Intended and Offered load and Forwarding Rates:
I note that the Intended load is what is being asked of the test, versus Offered load which is what the actual physical layer can do. Offered load is what should actual be transmitted.
The Intended Load is the number of frames per second in which an external source attempts to send to a DUT/SUT for forwarding to a specified output interface(s)."
The Offered Load is the number of frames per second that an external source can send to a DUT/SUT for forwarding to a specified output interface(s).
Note: 'There may occur an issue where -> Offered Load appears far too much lower than Intended Load.
I explain this may be causes when choosing -> Test Parameters -> Improve Time to Test -> Skip to next load when iteration fails.
When there is packet loss and because the iteration is configured due to this configuration to abruptly end, the configured rate is not caught by the analyzer.
If this is a concern, I recommend to deselect -> Test Parameters -> Improve Time to Test -> Skip to next load when iteration fails and retest in the same manner.'
The Forwarding Rate is the number of frames per second that a device can successfully send to the correct destination interface in response to a specified offered load.
The throughput is the fastest rate (Offered Load) at which the count of test frames transmitted by the DUT is equal to the number of test frames sent to it by the test equipment.
* I sincerely promise that this paper would be used for purely academic purposes only and not for any commercial applications.this copyright belong to original author. - from blog owner.
This content refer to "Channel Models A tutorial' paper of Raj Jain, jain@acm.org author in Google.
V1.0February 21, 2007
Channel Models A tutorial
1. The Basic Concepts
Wireless signal의 특성은 그것이 전파하는 (송수신간의) 매체를 통과하면서 변하게 된다. 이러한 특성은 송,수신 안테나 사이의 거리에 의하여 의존하게 되며, 그 거리에는 신호가 지나가는 경로와 환경(방해가능한 빌딩과 어떠한 물체 -> 이는 신호의 반사 및 흡수가 가능하다.) 적인 요소가 존재하여 채널의 특성을 변화시킨다.
만약 우리가 송수신 안테나사이의 매체 i.e 채널을 알수있다면, 입력신호를 앎으로써, 출력신호를 알수있게 된다.
Therefore, this model of the medium is called channel model.
In general, the power profile of the received signal can be obtained by convolving the power profile of
the transmitted signal with the impulse response of the channel. Convolution in time domain is
equivalent to multiplication in the frequency domain. Therefore, the transmitted signal x, after
propagation through the channel H becomes y
y(f)=H(f)x(f)+n(f)
일단, 송신신호와 수신신호와의 상관관계를 통하여 채널 추정이 가능하다.
위의 식에서 H(f)는 우리는 Chaneel responce라고 부를것이며, n(f)는 노이즈성분이다.
Note that x, y, H, and n are all functions of the signal frequency f.
The three key components of the channel response are path loss, shadowing, and multipath as explained below.
따라서, 우리는 채널에 영향을 주는 대략적인 3가지의 성분 path loss, shadowing, and multipath 를 통하여서, 채널을 추정할수가 있게 된다.
2.1 Path Loss
The simplest channel is the free space line of sight channel with no objects between the receiver and the transmitter or around the path between them. In this simple case, the transmitted signal attenuates since the energy is spread spherically around the transmitting antenna. For this line of sight (LOS) channel,the received power is given by:
먼저, 가장 간단한 형태의 채널을 정의해보자. 이는 자유공간 즉, 벽면도 없고 반사도 없는 그래서 손실도 없는 LOS (direct path propagation) 타입이다.
감쇠의 원인은 안테나의 전파(신호) 방사형태가 구면의 형태로 에너지를 확산시키기 때문에 P는 D^-2에 비례한다.
Here, Pt is the transmitted power,Gl is the product of the transmit and receive antenna field radiation patterns, λ is the wavelength, and d is the distance. Theoretically, the power falls off in proportion to the square of the distance. In practice, the power falls off more quickly, typically 3rd or 4th power of distance.
G1은 안테나의 방사패턴에 해당하는 Loss를 의미한다.
이론적으로 파워는 거리의 제곱에 비례하여 감소하지만, 사실 실제환경에서는 이보다 빠른 세제곱, 네제곱배로 감소한다.
The presence of ground causes some of the waves to reflect and reach the transmitter. These reflected
waves may sometime have a phase shift of 180 ° and so may reduce the net received power. A simple two-ray approximation for path loss can be shown to be:
자 이제 Free space 시나리오를 좀더 꼬아서 Ground 가 존재한다고 가정한다면, 이는 반사를 야기시킨다. -> 위상을 180도로 변화시키며, Power를 감소시킨다.
Here, ht and hr are the antenna heights of the transmitter and receiver, respectively.
Note that there are three major differences from the previous formula. First, the antenna heights have effect. Second, the wavelength is absent and third the exponent on the distance is 4.
이 공식의 앞전의 위의 공식과 3가지의 주요한 다른점이 존재한다.
안테나높이 고려, 파장고려X, 지수부4승.
2.1.5 Reflection from a ground plane (by Fundamentals Wirelsess Communication)
Consider a transmit and a receive antenna, both above a plane surface such as a road (Figure 2.6). When the horizontal distance r between the antennas becomes very large relative to their vertical displacements from the ground plane (i.e., height), a very surprising thing happens. In particular, the difference between the direct path length and the reflected path length goes to zero as r−1 with increasing r (Exercise 2.5). When r is large enough, this difference between the path lengths becomes small relative to the wavelength c/f .
Since the sign of the electric field is reversed on the reflected path5, these two waves start to cancel each other out. The electric wave at the receiver is then attenuated as r−2, and the received power decreases as r−4. This situation is particularly important in rural areas where base-stations tend to be placed on roads.
In general, a common empirical formula for path loss is:
그리고 이를 더욱 일반화한 형태로, 경험에 의한(실험에 의한) 공식은 아래와 같다.
위의 공식은 실제적인 path loss를 고려한 형태의 수신되는 신호의 Power를 의미한다.
Where P0 is the power at a distance 0 d and α is the path loss exponent.
The path loss is given by:
Path Loss 공식은 아래와 같이 dB표현식으로 주어진다
HerePL(d0 ) is the mean path loss in dB at distance 0 d . The thick dotted line in Figure A.1.2 shows the received power as a function of the distance from the transmitter.
If you want to know the more detail information about this section, please refer to Fundamentals Wireless Communication text book's chapter 2. It's free on website.
If there are any objects (such buildings or trees) along the path of the signal, some part of the transmitted signal is lost through absorption, reflection, scattering, and diffraction. This effect is called shadowing. As shown in Figure A.1.3, if the base antenna were a light source, the middlebuilding would cast a shadow on the subscriber antenna. Hence, the name shadowing.
쉐도잉은 송신 신호가 수신단으로 가기까지 어떠한 장애물이 존재하여, 송신신호가 흡수,반사,회절,흩어짐을 겪게 됨으로 소실되거나 딜레이되어 수신단에 도착하게 되는데 이로 인해 다른 크기와 위상의 신호가 중첩되어서, 이를 평균전력그래프로 그려보았을 때, "로그노말분포"로 나타나기에 흔히 우리는 로그노말쉐도잉이라고 부른다.
[보충]
Shadowing은 문자적 뜻은 음영 손실 (Shadowing Loss)을 의미하며, 현상은 전파 장애물 바로 뒤에 전파적인 그림자(음영)가 드리워져 나타나는 전파 손실을 말한다. 예를들면, 송신 전파가 산,빌딩 등 장애물의 불규칙적인 전파 반사면,산란체 등 때문에 수신 전파 전력이 평균을 중심으로 요동치는 현상 이라고 볼 수있다.
The net path loss becomes:
Here χ is a normally (Gaussian) distributed random variable (in dB) with standard deviation σ . χ represents the effect of shadowing. As a result of shadowing, power received at the points that are at the same distance d from the transmitter may be different and have a log-normal distribution. This phenomenon is referred to as log-normal shadowing.
2.1.6 Power decay with distance and shadowing
The previous example with reflection from a ground plane suggests that the received power can decrease with distance faster than r−2 in the presence of disturbances to free space. In practice, there are several obstacles between the transmitter and the receiver and, further, the obstacles might also absorb some power while scattering the rest. Thus, one expects the power decay to be considerably faster than r−2. Indeed, empirical evidence from experimental field studies suggests that while power decay near the transmitter is like r−2,
at large distances the power can even decay exponentially with distance.
The ray tracing approach used so far provides a high degree of numerical accuracy in determining the electric field at the receiver, but requires a precise physical model including the location of the obstacles. But here, we are only looking for the order of decay of power with distance and can consider an alternative approach. So we look for a model of the physical environment with the fewest parameters but one that still provides useful global information about the field properties. A simple probabilistic model with two parameters of the physical environment, the density of the obstacles and the fraction of energy each object absorbs, is developed in Exercise 2.6. With each obstacleabsorbing the same fraction of the energy impinging on it, the model allows
us to show that the power decays exponentially in distance at a rate that is proportional to the density of the obstacles. With a limit on the transmit power (either at the base-station or at the mobile), the largest distance between the base-station and a mobile at which communication can reliably take place is called the coverage of the cell.
For reliable communication, a minimal received power level has to be met and thus the fast decay of power with distance constrains cell coverage. On the other hand, rapid signal attenuation with distance is also helpful; it reduces the interference between adjacent cells. As cellular systems become more popular, however, the major determinant of cell size is the number of mobiles in the cell. In engineering jargon, the cell is said to be capacity limited instead of coverage limited. The size of cells has been steadily decreasing, and one talks
of micro cells and pico cells as a response to this effect. With capacity limited cells, the inter-cell interference may be intolerably high. To alleviate the inter-cell interference, neighboring cells use different parts of the frequency spectrum, and frequency is reused at cells that are far enough. Rapid signal attenuation with distance allows frequencies to be reused at closer distances. The density of obstacles between the transmit and receive antennas depends very much on the physical environment. For example, outdoor plains have very little by way of obstacles while indoor environments pose many obstacles.
This randomness in the environment is captured by modeling the density of obstacles and their absorption behavior as random numbers; the overall phenomenon is called shadowing.6 The effect of shadow fading differs from multipath fading in an important way. The duration of a shadow fade lasts for multiple seconds or minutes, and hence occurs at a much slower time-scale compared to multipath fading.
2.3 Multi-path
The objects located around the path of the wireless signal reflect the signal. Some of these reflected waves are also received at the receiver. Since each of these reflected signals takes a different path, it has a different amplitude and phase.
반사되는 신호들이 서로 다른 경로를 가지므로, 다른 위상,크기를 가진 신호가 되기에 이를 다중경로 페이딩이라고 부른다.
[보충] : Multi-path Fading
서로 다른 경로를 따라 수신된 전파들이 여러 물체에 의한 다중 반사로 인해 서로다른 진폭,위상,입사각,편파 등이 간섭
(보강간섭,소멸간섭)을 일으켜 불규칙 요동치는 현상
Depending upon the phase, these multiple signals may result in increased or decreased received power at the receiver. Even a slight change in position may result in a significant difference in phases of the signals and so in the total received power. The three components of the channel response are shown clearly in Figure A.1.4. The thick dashed line represents the path loss. The log-normal shadowing changes the total loss to that shown by the thin dashed line. The multipath finally results in variations shown by the solid thick line. Note that signal strength variations due to multipath change at distances in the range of the signal wavelength.
그래서 아래 그림과 같은 형태의 수신 파워를 보인다. 아래의 그래프는 x축 거리가 멀어짐에 따른 y축 수신파워/송신파워의 db비를 나타낸 그래프이다. 이를 통하여 각 채널에 영향을 주는 3가지 성분들로 인하여 입력신호가 어떻게 수신되는지를 대략적으로 알수가 있다.
Since different paths are of different lengths, a single impulse sent from the transmitter will result in multiple copies being received at different times as shown in Figure A.1.5
아래의 그림은 송신 신호가 수신측에서 Multipath를 겪고서 어떻게 페이딩현상으로 나타나는지를 보여준다.
The maximum delay after which the received signal becomes negligible is called maximum delay spread τmax. A large τmax indicates a highly dispersive channel. Often root-mean-square (rms) value of the delay-spread τrms is used instead of the maximum.
송순 후에 multipath fading으로 너무 많은 딜레이와 감쇄효과가 있어서 무시해도 되는 수신신호파워를 우리는 τmax 라고 부른다.
3. Tapped Delay Line Model
One way to represent the impulse response of a multipath channel is by a discrete number of impulses as follows:
Note that the impulse response h varies with time t. The coefficients ci(t) vary with time. There are N coefficients in the above model. The selection of the N and delay values τi depends upon what is considered a significant level. This model represents the channel by a delay line with N taps. For example, the channel shown in Figure A.1.5 can be represented by a 4-tap model as shown in Figure A.1.6.
멀티 패스 채널의 임펄스 응답의 표현은 위의 식처럼, 임펄스들의 이산적인 합으로 표현될수가 있다.
[보충] : 왜 임펄스 함수인가?
흔히 채널은 시스템으로 표현할수가 있다고 한다. 왜냐하면, 입력신호를 어떤 시스템에 넣고 (채널) 출력신호를 보는 과정이 통신의 송/수신과 매우 흡사하며, 이를 수학적으로 모델링하여 나타내면 간단 명료하게 채널의 특성을 보여줄수 있기 때문이다. 임펄스 응답이란? 시스템에 단위 임펄스함수를 인가하였을 때의 출력을 의미하며, 임펄스 응답에 대한 '푸리에변환'은 통신의 주파수 특성 (전달함수 H)와 같다. 그래서 임펄스 응답을 알면 우리는 주어진 입력에 대한 출력을 쉽게 구할수 있기 때문에 우리는 임펄스 함수를 사용하게 되었다.
If the transmitter, receiver, or even the other objects in the channel move, the channel characteristics change. The time for which the channel characteristics can be assumed to be constant is called coherence time. This is a simplistic definition in the sense that exact measurement of coherence time requires using the auto-correlation function.
만약 송/수신기(ex.안테나)가 움직이면 채널의 특성도 변하게 된다. 그래서 우리는 채널이 제한된 특성을 가지고 있는 시간을 하나의 척도로 명명하였는데 이것이 coherence time 이다.
coherence bandwidth 도 이와 매우 유사하다.
For every phenomenon in the time domain, there is a corresponding phenomenon in the frequency domain. If we look at the Fourier transform of the power delay profile, we can obtain the frequency dependence of the channel characteristics. The frequency bandwidth for which the channel characteristics remain similar is called coherence bandwidth. Again, a more strict definition requires determining the auto-correlation of the channel characteristics. The coherence bandwidth is inversely related to the delay spread. The larger the delay spread, less is the coherence bandwidth and the channel is said to become more frequency selective.
delay spread는 LOS와 비교하였을 때, 위의 Figure A.1.6과 같이 지연되어 수신되는 현상을 말한다.
delay spread가 크다면 coherencebandwidth 은 작으며, 이때 채널을 우리는 frequency selective하다고 말한다.
4. Doppler Spread
The power delay profile gives the statistical power distribution of the channel over time for a signal transmitted for just an instant. Similarly, Doppler power spectrum gives the statistical power distribution of the channel for a signal transmitted at just one frequency f. While the power delay profile is caused by multipath, the Doppler spectrum is caused by motion of the intermediate objects in the channel. The Doppler power spectrum is nonzero for (f-fD, f+fD), where fD is the maximum Doppler spread or Doppler spread.
The coherence time and Doppler spread are inversely related:
coherence time과 Doppler Spread는 서로 역수관계를 가진다.
Thus, if the transmitter, receiver, or the intermediate objects move very fast, the Doppler spread is large and the coherence time is small, i.e., the channel changes fast.
Table A.1.1 lists typical values for the Doppler spread and associated channel coherence time for two WiMAX frequency bands. Note that at high mobility, the channel changes 500 times per second, requiring good channel estimation algorithms
높은 대역으로 Carrier Frequency가 갈수록 Coherence Time은 작으며, Max Doppler Spread가 높을수록 채널의 안정적인 시간 = 주파수가 Flat한 시간이 적다.
여기에선 Coherence Time과 Doppler Spread만을 비교하였으며, Doppler Spread에 대한 자세한 정보가 필요하다면 위에서 소개한 책의 Chapter 2.1.4를 참고하기 바란다.
in this Tutorial, we just handled the comparison with Coherence Time and Doppler Spread. If you want to learn the Doppler Spread, you can easier understand though the textbook which we already introduced.
솔루션들이필요하다. 그리고우리는어떻게 Cross Layer framework에서불완전한스케줄링을사용할것인지를시연하고, 최근에개발된분산알고리즘에대해서도알아볼것이다. 그리고마지막으로우리는 a set of open research problems을토의함으로써마칠것이다.
즉, 다시말해서위논문은아래의 5가지단계를따른다.
1) 기회주의적스케줄링을살펴봄
2) 멀티홉무선네트워크에서의자원배분문제를알아봄
3) 위의자원배분문제를 Loosely-coupled 된 Cross Layer에서다시자원배분문제를접근함
4) 그리고어떻게불완전한스케줄링알고리즘을사용했는지, 분산알고리즘은무엇인지설명할것이다.
5) 마지막으로이와함께고민할수있는Open Problems을다룸으로마친다.
1. 기회주의적스케줄링 ‘Opportunistic scheduling’ 의의미는?
무선시스템은 무선채널의 시변특성, 한정된 자원의 공유, 페이딩 등의 특성으로 인해 유선시스템과 비교할 때 높은 대역폭을 사용자들에게 제공하기에 어려운 문제점들을 안고 있다. 이러한 문제점을 해결하기 위해 제시된 무선채널에서의 스케줄링 방법이 Opportunistic Scheduling (기회주의적 스케줄링) 또는 Channel-Aware Scheduling 방식이다
기회주의적 스케줄링이란 하나의 엑세스 포인트가 여러 사용자를 TDMA 방식을 통해 동시에 수용할 경우, 매 타임슬롯마다 가장 채널 상태가 좋은 사용자들을 “기회주의”적으로 선택하여 서비스를 제공하는 방식을 말한다.기존의 방식에서는 사용자들의 채널정보를 알지 못하기 때문에 정적인 시분할 방식을 사용하였다. 그에 따라 채널속도가 빠르지 않은 사용자가 채널을 점유할 경우, 그 효율이 떨어지는 단점이 있었다. 이를 극복하기 위해서 매 타임슬롯마다 사용자들이 자신의 채널정보를 엑세스 포인트로 피드백하고, 엑세스 포인트는 각 사용자들로부터 받은 정보를 토대로 가장 좋은 채널상태를 갖는 사용자를 골라서 서비스를 하게 된다.
기회주의적 스케줄링을 구현하는 방법에 있어서 시스템의 처리량을 최대화하는 방식과 사용자간의 공평성을 맞추는 방식 사이의 적절한 조화를 위한 노력이 있어왔으며 또한 QoS와 best effort 트래픽을 동시에 지원하기 위한 노력이 있어왔다. 반면, 현재까지 개발된 많은 알고리즘들은 사용자수가 변하지 않고 각 사용자들의 큐가 다 비워지지 않는다고 가정하는 패킷레벨에서의 방식들이었다. 반면, 실제 시스템에서는 각 사용자들의 트래픽이 유한한 서비스 시간 또는 파일사이즈를 갖고 큐에 랜덤하게 도착하고 서비스를 다 받으면 큐를 떠나게 된다. 이를 효과적으로 분석하기 위해서는 패킷레벨에서의 분석 대신 플로우 레벨에서의 분석이 필요하다. 그에 따라, 본 논문에서 다루는 것이 기회주의적 무선시스템에서의 QoS와 best effort 트래픽의 통합과 그에 따른 문제점의 플로우레벨에서의 분석이다.
A distributed algorithm is an algorithm designed to run on computer hardware constructed from interconnected processors. Distributed algorithms are used in many varied application areas of distributed computing, such as telecommunications, scientific computing, distributed information processing, and real-time process control. Standard problems solved by distributed algorithms include leader election, consensus, distributed search, spanning tree generation, mutual exclusion, and resource allocation.[1]
I. INTRODUCTION
Optimization-based 의접근법은지금까지통신네트워크영역에서 “Resource allocation problem” 해결을위해서광범위하게연구되어왔다. 예를들면, Internet congestion control은시스템의성능을최대한으로끌어내는convex optimization problem 으로 distributed primal or dual solutions 자원배분문제를어떻게해결하는가에대한모범적인예로써생각할수가있다. 이런류의접근법(실험법) 은 TCP(transmission control protocol)에대한깊은이해와향상된혼잡제어(congestion control) 라는솔루션을보여준다.[1-6]
어쨌든질문의핵심은앞서말한접근법이통합된 multi-hop wireless networks에서 *a clean-slate design of the protocol stack으로적용될수있다는점이다. 사실, Internet setting에서의그러한기술의직접적인어플리케이션을허용하지않는무선통신의맥락에서있어서꽤특별한도전들이있다. 특히, 무선매체는본질적으로유저들의데이터송신에의한간섭이많이일어나는다중접속매체로써, 채널의 capacity가 time-varying 의성격을보인다. 이러한이유로, 무선매체는사용자와네트워크 Layer간의상호의존성을띄기때문에기존의유선과는반대의성격을가진다. 하지만, 이런어려움에도불구하고, 최근에통합및최적화된형태로써의 Multiple layer들의무선자원을자유로이공유하거나넘나드는(Cross Layer개념) 진보된결과들을보여준다. 이와관련된흥미로운내용은섹션3에서설명한다.
(The solution of such an optimization framework will itself exhibit a layered structure with only a limited degree of cross-layer coupling.)
*The notion of a clean-slate design becomes especially attractive for multi-hop wireless networks, where the burdens of legacy systems are far less than for the Internet.
; 특히, convex programming에서Lagrange duality은복잡한최적화문제를간단한여러가지문제로써분해하는중요한핵심도구이다. 하지만, 우리는종종우리는이것만으로문제를 100% 해결하는것에는부족하단것을안다. 왜냐하면, 유선네트워크와는반대로, 많은무선네트워크에서의 Cross-layer control problems 은 not convex (볼록) 않기때문이다.
예를든다면, 무선네트워크에서의간섭문제들로인하여, 각각의시간에대해서활성화되어야하는링크들의부분집합들에대한선택에있어서정확히선택해야하는정교한스케줄링 mechanisms을요구하는것같은것이다. 무선네트워크에서, 각링크들의 capacity는신호와간섭레벨에의존적이고, 그러한것들은파워와링크의전송스케줄에의존적이다. 그래서 link capacity, power assignment, and the transmission schedule 에서의관계들은전형적으로 non-convex 하다.
6)Heavy-traffic limits are used to obtain realistic and efficient solutions to the cross-layer control problem.
cross-layer optimization 는 최근 사이에 꽤 큰 이슈로 발전 되었고, 이를 위한 포괄적인 조사는 공간적인 (space constraints) 제한을 가진다. 따라서, 이 paper에선 모두를 다 조사하진 못했다. 오히려, 포커스는 주요한 이슈와 도전들, 그리고 테크닉과 open problem들에 대해서 독자들에게 알려주는 정보전달에 대해서 맞춰져 있다. [7]을 참조하길 바란다.
Section III: we investigate the joint congestion-control and scheduling problem in multi-hop wireless networks.
섹션3의내용은주로 the cross-layer problem 를 a congestion control component and a scheduling component 2가지로깔끔하게분해하며접근한다. 하지만, non-convexity성격때문에실제네트워크에서스케줄링은매우어렵지만 cross-layer solution으로심플하지만불완전한해결법으로어느정도접근해본다.
Section IV: 당연히이부분은앞으로더보완되고다듬어져가야한다.
Section V: recent developments in obtaining imperfect distributed scheduling policies with provably achievable throughput bounds.
We then conclude with a set of open problems.
II. OPPORTUNISTIC SCHEDULING FOR CELLULAR WIRELESS NETWORKS
오랫동안 multiuser scheduling problem은산업과학교에서많은조명을받아왔다. 그리고 multiuser scheduling problem은무선네트워크에서독특한특징으로써많은동기부여를받아왔다. : 자원의크기, mobile 유저의간섭문제, 시변채널의조건들(이동성과페이딩으로인한)
게다가, 가정해보자. 유저들의 base station 으로부터의타임슬롯시스템과다운링크통신에대해서가정해보자.
base station은채널조건을기반으로어느유저가전송이가능한지결정할수가있다. 이아이디어는 SINR기반의채널컨디션에따라서수신단으로의전송을베이스스테이션이주어진 BER을만족시키며높은속도로전송을허용하는것을의미한다. 이것은 Base Station 이기회주의적기법으로, 즉높은네트워크성능유지를위하여채널의조건을이용한다는의미이다.
이와는달리기존의전통적인방법에선, 채널의가변성을제거하는것이주된관심사였다.
(예를들면, spread spectrum, repetitive coding, and power averaging)
Opportunistic scheduling 에대한설명~ (앞장참고)
우리의초점은 Downlink에서의 base station 전송시나리오로한정하며, 유/무한 backlogged cased을위한 Opportunistic scheduling solutions을볼것이다.
A. Infinite-Backlog Case
Infinite-Backlog Case 종종통신시스템분야에서프로토콜의성능평가와최대의성능량을보기위하여사용된다.
• Fairness in utility: Each user receives at least a fraction of the aggregate utility value [11], [13].
• Minimum data rate requirement: Each user receives a minimum data rate of bps [13].
• Proportional fairness: Here, the objective is to achieve a solution that is proportionally fair, i.e., increasing the mean throughput of one user from the optimal level by results in a cumulative percentage decrease by greater than of the mean throughput of other users [14]. It turns out that such a solution is achieved when the optimization problem is to maximize the sum of the logarithms of the expected rates (or the product of the expected rates), i.e.,
게다가, 시스템이증가하는경우와초기에증가하는총네트워크처리량정책안에서, 주어진 delay조건을위반하며,
Moreover, for a given delay violation constraint, when the number of users in the system increases, the total network throughput under policy (1) initially increases, and then eventually decreases to zero, but not so under the QLB policy. This should not be entirely surprising since index policies of the form (1) are agnostic to the delays incurred for different users and may not serve users whose queues are building up fast enough to remain within a delay violation probability.
또한, 주어진지연위반제약조건, 시스템증가에있는사용자의수가정책에따라전체네트워크처리량이처음증가할때, 그리고결국그렇게 QLB 정책하에서제로로감소하지만. 폼의인덱스정책이다른사용자에따른지연독립적이며, 해당대기열지연시간위반확률내에남아있는만큼빠르게구축하는사용자에게서비스를제공할수없습니다때문에이것은전혀놀라운일이안된다.
..작성중
REFERENCES
[1] F. P. Kelly, A. Maulloo, and D. Tan, “Rate control in communication networks: Shadow prices, proportional fairness and stability,” J. Oper. Res. Soc., vol. 49, pp. 237–252, 1998.
[2] H. Yaiche, R. Mazumdar, and C. Rosenberg, “A game theoretic framework for bandwidth allocation and pricing in broadband networks,” IEEE/ACM Trans. Netw., vol. 8, no. 5, pp. 667–678, Oct. 2000.
[3] S. H. Low and D. E. Lapsley, “Optimization flow control-I: Basic algorithm and convergence,” IEEE/ACM Trans. Netw., vol. 7, no. 6, pp. 861–874, Dec. 1999.
[4] S. Kunniyur and R. Srikant, “End-to-end congestion control schemes: Utility functions, random losses and ECN marks,” in Proc. IEEE INFOCOM, Tel-Aviv, Israel, Mar. 2000, pp. 1323–1332.
[5] S. H. Low and R. Srikant, “A mathematical framework for designing a low-loss low-delay Internet,” Netw. Spatial Econom., vol. 4, no. 1, pp. 75–102, Mar. 2004.
[6] R. Srikant, The Mathematics of Internet Congestion Control. Cambridge, MA: Birkhauser, 2004.
[7] M. Chiang, S. H. Low, R. A. Calderbank, and J. C. Doyle, “Layering as optimization decomposition,” Proc. IEEE, Dec. 2006, to be published.
[8] R. Knopp and P. Humblet, “Information capacity and power control in single-cell multiuser communications,” in Proc. ICC, 1995, pp. 331–335.
[9] P. Bender, P. Black, M. Grob, R. Padovani, N. Sindhushayana, and A. Viterbi, “CDMA/HDR: A bandwidth-efficient high-speed wireless data service for nomadic users,” IEEE Commun. Mag., pp. 70–77, Jul. 2000.
[10] S. Borst and P. Whiting, “Dynamic rate control algorithms for HDR throughput optimization,” in Proc. IEEE INFOCOM, Alaska, Apr. 2001, pp. 976–985.
[11] ——, “The use of diversity antennas in high-speed wireless systems: Capacity gains, fairness issues, multi-user scheduling,” Bell Laboratories Technical Memorandum, 2001.
[12] X. Liu, E. K. P. Chong, and N. B. Shroff, “Opportunistic transmission scheduling with resource-sharing constraints in wireless networks,” IEEE J. Sel. Areas Commun., vol. 19, no. 10, pp. 2053–2064, Oct. 2001.
[13] ——, “A framework for opportunistic scheduling in wireless networks,” Comput. Netw., vol. 41, no. 4, pp. 451–474, Mar. 2003.
[14] A. Jalali, R. Padovani, and R. Pankaj, “Data throughput of CDMA-HDR a high efficiency-high data rate personal communication wireless system,” in Proc. IEEE Veh. Technol. Conf., 2000, pp. 1854–1858.
[15] L. Tassiulas and A. Ephremides, “Stability properties of constrained queueing systems and scheduling policies for maximum throughput in multihop radio networks,” IEEE Trans. Autom. Control, vol. 37, no. 12, pp. 1936–1948, Dec. 1992.
[16] M. Andrews, K. Kumaran, K. Ramanan, A. Stolyar, P. Whiting, and R. Vijayakumar, “Providing quality of service over a shared wireless link,” IEEE Commun. Mag., vol. 39, pp. 150–153, Feb. 2001.
[17] S. Shakkottai and A. Stolyar, “Scheduling for multiple flows sharing a time-varying channel: The exponential rule,” Translations of the AMS, 2001, a volume in memory of F. Karpelevich.
[18] ——, “Scheduling of a shared a time-varying channel: The exponential rule stability,” in Proc. INFORMS Appl. Prob. Conf., New York, Jul. 2001.
[19] R. Buche and H. J. Kushner, “Control of mobile communication systems with time-varying channels via stability methods,” IEEE Trans. Autom. Control, vol. 49, no. 11, pp. 1954–1962, Nov. 2004.
[20] A. L. Stolyar, “Maximizing queueing network utility subject to stability: Greedy primal-dual algorithm,” Queueing Syst., vol. 50, no. 4, pp. 401–457, 2005.
[21] S. Borst, “User-level performance of channel-aware scheduling algorithms in wireless data networks,” IEEE/ACM Trans. Netw., vol. 13, no. 3, pp. 636–647, Jun. 2005.
[22] S. Shakkottai, “Effective capacity and QoS for wireless scheduling,” preprint, 2004.
[23] L. Ying, R. Srikant, A. Eryilmaz, and G. Dullerud, “A large deviations analysis of scheduling in wireless networks,” Trans. Inf. Theory, 2005, Earlier versions of the paper appeared in the IEEE CDC 2004, IEEE
CDC 2005 and IEEE ISIT 2006, submitted for publication.
[24] S. Sarkar and L. Tassiulas, “End-to-end bandwidth guarantees through fair local spectrum share in wireless ad-hoc networks,” in Proc. IEEE Conf. Decision and Control, Maui, HI, Dec. 2003, pp. 564–569.
[25] Y. Yi and S. Shakkottai, “Hop-by-hop congestion control over a wireless multi-hop network,” in Proc. IEEE INFOCOM, Hong Kong, Mar. 2004, pp. 2548–2558.
[26] Y. Xue, B. Li, and K. Nahrstedt, “Price-based resource allocation in wireless ad hoc networks,” in Proc. 11th Int. Workshop on Quality of Service, also Lecture Notes in Computer Science. New York: Springer-Verlag, vol. 2707, Monterey, CA, Jun. 2003, pp. 79–96.
[27] L. Chen, S. H. Low, and J. C. Doyle, “Joint congestion control and media access control design for wireless ad hoc networks,” in Proc. IEEE INFOCOM, Miami, FL, Mar. 2005, pp. 2212–2222.
[28] X. Lin and N. B. Shroff, “Joint rate control and scheduling in multihop wireless networks,” in Proc. IEEE Conf. Decision and Control, Paradise Island, Bahamas, Dec. 2004, pp. 1484–1489.
[29] ——, “The impact of imperfect scheduling on cross-layer rate control in multihop wireless networks,” in Proc. INFOCOM, Miami, FL, Mar. 2005, pp. 1804–1814.
[30] A. Eryilmaz and R. Srikant, “Fair resource allocation in wireless networks using queue-length-based scheduling and congestion control,” in Proc. IEEE INFOCOM, Miami, FL, Mar. 2005, pp. 1794–1803.
[31] A. Eryilmaz and R. Srikant, “Joint congestion control, routing and MACfor stability and fairness in wireless networks,” IEEE J. Sel. Areas Commun., vol. 24, no. 8, pp. 1514–1524, Aug. 2006.
[32] I. Paschalidis, W. Lai, and D. Starobinski, “Asymptotically optimal transmission policies for low-power wireless sensor networks,” in Proc. IEEE INFOCOM, Miami, FL, Mar. 2005, pp. 2458–2469.
[33] M. J. Neely, E. Modiano, and C. Li, “Fairness and optimal stochastic control for heterogeneous networks,” in Proc. IEEE INFOCOM, Miami, FL, Mar. 2005, pp. 1723–1734.
[34] M. Johansson and L. Xiao, “Scheduling, routing and power allocation for fairness in wireless networks,” in Proc. IEEE Veh. Technol. Conf.–Spring, Milan, Italy, May 2004, pp. 1355–1360.
[35] T. Bonald and L. Massoulie, “Impact of fairness on Internet performance,” in Proc. ACM Sigmetrics, Cambridge, MA, Jun. 2001, pp. 82–91.
[36] J. Mo and J.Walrand, “Fair end-to-end window-based congestion control,” IEEE/ACM Trans. Netw., vol. 8, no. 5, pp. 556–567, Oct. 2000.
[37] M. J. Neely, E. Modiano, and C. E. Rohrs, “Dynamic power allocation and routing for time varying wireless networks,” in Proc. IEEE INFOCOM, San Francisco, CA, Apr. 2003, pp. 745–755.
[38] R. L. Cruz and A. V. Santhanam, “Optimal routing, link scheduling and power control in multi-hop wireless networks,” in Proc. IEEE INFOCOM, San Francisco, CA, Apr. 2003, pp. 702–711.
[39] S. Toumpis and A. J. Goldsmith, “Capacity regions for wireless ad hoc networks,” IEEE Trans. Wireless Commun., vol. 2, no. 4, pp. 736–748, Jul. 2003.
[40] X. Lin and N. B. Shroff, “The impact of imperfect scheduling on cross-layer congestion control in wireless networks,” IEEE/ACM Trans. Netw., vol. 14, no. 2, pp. 302–315, Apr. 2006.
[41] G. Sharma, R. R. Mazumdar, and N. B. Shroff, “Maximum weighted matching with interference constraints,” in Proc. IEEE Int. Workshop Foundations and Algorithms ForWireless Networking, Pisa, Italy,Mar. 2006, pp. 70–74.
[42] C. H. Papadimitriou and K. Steiglitz, Combinatorial Optimization: Algorithms and Complexity. Englewood Cliffs, NJ: Prentice-Hall, 1982. LIN et al.: A TUTORIAL ON CROSS-LAYER OPTIMIZATION IN WIRELESS NETWORKS 1463
[43] L. Xiao, M. Johansson, and S. Boyd, “Simultaneous routing and resource allocation via dual decomposition,” in Proc. 4th Asian Control Conf., Singapore, Sep. 2002, pp. 29–34.
[44] M. Chiang, “Balancing transport and physical layer in multihop wireless networks: Jointly optimal congestion and power control,” IEEE J. Sel. Areas Commun., vol. 23, no. 1, pp. 104–116, Jan. 2005.
[45] ——, “Geometric programming for communication systems,” Foundations and Trends in Communications and Information Theory, vol. 2, no. 1–2, pp. 1–154, Jul. 2005.
[46] M. Arisoylu, T. Javidi, and R. L. Cruz, “End-to-end and MAC-layer fair rate assignment in interference limited wireless access networks,” in Proc. IEEE ICC , Istanbul, Turkey, Jun. 2006, to be published.
[47] X. Wang and K. Kar, “Cross-layer rate control for end-to-end proportional fairness in wireless networks with random access,” in Proc. ACM Mobihoc, Urbana-Champaign, IL, May 2005, pp. 157–168.
[48] J. W. Lee, M. Chiang, and R. A. Calderbank, “Jointly optimal congestion and contention control in wireless ad hoc networks,” IEEE Commun. Lett., vol. 10, no. 3, pp. 216–218, Mar. 2006.
[49] J. Zhang and D. Zheng, “A stochastic primal-dual algorithm for joint flow control andMAC design in multi-hop wireless networks,” in Proc. Conf. Inf. Sci. Syst., Princeton, NJ, Mar. 2006.
[50] L. Bui, A. Eryilmaz, R. Srikant, and X. Wu, “Joint congestion control and distributed scheduling in multihop wireless networks with a nodeexclusive interference model,” in Proc. IEEE INFOCOM, 2006.
[51] E. Leonardi, M. Mellia, F. Neri, and M. A. Marsan, “On the stability of input-queued switches with speed-up,” IEEE/ACM Trans. Netw., vol. 9, no. 1, pp. 104–118, Feb. 2001.
[52] X. Wu and R. Srikant, “Regulated maximal matching: A distributed scheduling algorithm for multi-hop wireless networks with node-exclusive spectrum sharing,” in Proc. IEEE Conf. Decision Control, 2005, pp. 5342–5347.
[53] T. Weller and B. Hajek, “Scheduling non-uniform traffic in a packetswitching system with small propagation delay,” IEEE/ACM Trans. Netw., pp. 813–823, Dec. 1997.
[54] J. Dai and B. Prabhakar, “The throughput of data switches with and without speedup,” in Proc. IEEE INFOCOM, 2000, pp. 556–564.
[55] X. Wu, R. Srikant, and J. R. Perkins, “Queue-length stability of maximal greedy schedules in wireless network,” in Proc. Inf. Theory Appl. Inaugural Workshop, Feb. 2006, Univ. California, San Diego.
[56] P. Chaporkar, K. Kar, and S. Sarkar, “Achieving queue length stability through maximal scheduling in wireless networks,” in Proc. Inf. Theory Appl. Inaugural Workshop, Feb. 2006, Univ. California,
San Diego.
[57] ——, “Throughput guarantees in maximal scheduling in wireless networks,” in Proc. 43rd Annu. Allerton Conf. Commun., Control, Comput., Monticello, IL, Sep. 2005.
[58] X. Lin and S. Rasool, “Constant-time distributed scheduling policies for ad hoc wireless networks,” IEEE CDC 2006. [Online]. Available: http://min.ecn.purdue.edu/~linx/papers.html, submitted for publication
[59] X. Lin, N. Shroff, and R. Srikant, “On the connection-level stability of congestion-controlled communication networks,” IEEE Trans. Inf. Theory, 2006, submitted for publication.
[60] P. R. Kumar and T. I. Seidman, “Dynamic instabilities and stabilization methods in distributed real-time scheduling of manufacturing systems,” IEEE Trans. Autom. Control, pp. 289–298, Mar. 1990.
[61] A. Rybko and A. Stolyar, “Ergodicity of stochastic processes describing the operation of open queueing networks,” Problems of Information Transmission, vol. 28, pp. 199–220, 1992, translated from
Problemy Peredachi Informatsii, vol. 28, no. 3, pp. 3–26, 1992.
[62] A. Eryilmaz, E. Modiano, and A. Ozdaglar, “Distributed control for throughput-optimality and fairness in wireless networks,” preprint, 2006.
[63] Y. Yi, G. de Veciana, and S. Shakkottai, “Learning contention patterns and adapting to load/topology changes in a MAC scheduling algorithm,” preprint, 2006.
[64] J.-W. Lee, R. R. Mazumdar, and N. B. Shroff, “Downlink power allocation for multi-class CDMA wireless networks,” in Proc. IEEE INFOCOM, 2002, vol. 3, pp. 1480–1489.
[65] ——, “Opportunistic power scheduling for multi-server wireless systems with minimum performance constraints,” in Proc. IEEE INFOCOM, Hong Kong, China, 2004, pp. 1067–1077.
[66] M. Chiang, S. Zhang, and P. Hande, “Distributed rate allocation for inelastic flows: Optimization frameworks, optimality conditions, and optimal algorithms,” in Proc. IEEE INFOCOM,Miami, FL, Mar. 2005,
라그랑지안 함수란 일정 제약하에서 극대화나 극소화 문제를 풀 때 쓰는 테크닉입니다. 그래서 경제수학책의"constrained optimisation"의 장에 있습니다.
가장 간단한 예로 예산제약하의 효용 극대화를 생각해 봅시다.
U=U(X,Y)를 objective function이라 하고, 제약식(constraint)을 PxX+PyY=M이라 할 때
라그랑지안 함수를 L 이라 하면, (이 경우는 어떤 제약하의 극대화 케이스입니다.)
L=U(X,Y)+λ(M-PxX-PyY)
라고 표현합니다. (λ(람다, Lambda))
다시 말해 L= objective function+λ(constraint)로 표현되는 것이 라그랑지안 함수인 것입니다.
그리고, 각각 X와 Y, 그리고 λ에 대해 편미분을 하면
Lx=Ux-Pxλ.=0
Ly=Uy-Pyλ=0
PxX+PyY=M
의 세가지 식이 도출되겠죠.
세 식을 X와 Y에 대해 풀면, 그 답인 X,Y값이 예산제약하에 효용을 극대화 하는 X, Y(상품량)이 되는 겁니다. 첫번째와 두번째 식을 풀면 경제학 책에 많이 나오는 (λ=) Ux/Px= Uy/Py, Ux/Uy=Px/Py 식을 도출할 수 있습니다.
그럼, 람다(λ) 값은 경제학적 의미에서 뭐냐? 람다는 예산제약이 1단위 증가할 때 목적함수의 최적값이 얼마나 증가하는지를 알려줍니다. 즉, 예산이 1원(또는 1달러) 증가할 경우, 목적함수인 효용함수의 최적값(optimal utility)이 λ단위만큼 증가한다는 의미입니다.
매우 유용한 방법이기 때문에 경제수학책을 참고하셔서 익혀놓으시면 공부하시는데 상당히 도움이 되실 겁니다.
(참고로 쉬운 예제 하나)
소비자 갑돌이의 효용함수는 U(X,Y)=xy라 합시다.
그가 가진 돈(예산)이 총 90원이고, 사고(x)재화의 가격은 3원, 배(y)재화의 가격은 5원이라 합시다.
이 예산제약상황을 식으로 나타내면
3x+5y=90
즉, max U=xy
s.t. 3x+5y=90
(다시 말해서, 이문제는 갑돌이의 예산제약식하에서 그의 효용을 극대화하기 위해서는 사과(x)와 배(y)를 얼마만큼 소비해야 하느냐...하는 문제입니다.)
즉, 사과(x재화)는 15개, 배(y재화)는 9개를 소비할 때 갑돌이가 가지고 있는 예산하에서 갑돌이의 효용이 극대화됩니다. (이때 효용은 135(그의 효용식은 x곱하기 y니까)가 되겠죠)
라그랑주 역학(Lagrangian mechanics)은 조제프 루이 라그랑주가 고전역학을 새롭게 공식화하여 그의 논문 《해석 역학》을 통해 1788년에 발표한 이론이다. 라그랑주 역학에서는라그랑지언을 구해 라그랑주 방정식에 넣어 풀어냄으로써 물체의 궤적을 구할 수 있다.
**라그랑주 방정식**
라그랑주 역학의 운동방정식을 라그랑주 방정식(Lagrange's equation)이라고 한다. 자세한 형태는 아래와 같다.
보존계의 경우, 라그랑주 방정식은 다음과 같은 형태를 가지고, 이러한 방정식을오일러-라그랑주 방정식(Euler-Lagrange equation)이라고 한다.
어떤 운동방정식을 주는 라그랑지언은 유일하지 않다. 예를 들어, 고전역학의 라그랑지언 와 다음과 같은 좌표와 시간만의 임의의 함수 의 시간에 대한 전미분을 포함하는 라그랑지언
전미분은 쉽게 말하자면 주어진 함수 f의 미분소 df를 의미합니다. 이 df라는 양은 말 그대로 함수의 변화량을 재는 양으로,기하학적인 양입니다. 무슨 의미냐 하면, df라는 양은 좌표계의 선택에 의존하지 않고 순수하게 두 (가까운) 점 사이의 f의 변화량을 잰다는 의미입니다.
전미분과 대응되는 개념으로 편미분이란 것이 있습니다. 편미분은 함수를 특정 방향 혹은 특정 변수로 미분하여 얻은 값을 뜻합니다. 이 양은 그 정의부터가 필연적으로 좌표계에 의존하게 되어있습니다. 따라서 편미분은 (그 값들이 특별하게 얽혀있지 않는 한) 순수하게 기하학적인 양을 나타낼 수 없습니다.
때문에전미분이란 양은 기하학적, 물리적으로 아주 중요한 의미를 갖습니다. 사실 물리에서 좌표계는 물리현상을 설명하기 위한 보조적인 수단이며, 현상의 본질이 될 수 없습니다. 예를 들어서 우리의 일상적인 척도로 보면 직교좌표계가 쓰기 편하지만, 전체 지구 레벨로 보면 구면좌표계를 쓰는 것이 위치를 표현하기에 훨씬 적당하지요. 그래서 지구 레벨에서는 위치를 위도, 경도, 고도라는 개념으로 위치를 표현합니다. 이렇듯 좌표계의 선택은 언제나 달라질 수 있는데, 물리에서는 그러한 인위적인 선택에 영향을 받지 않는 양이 가장 유용한 양이기 때문에 자연스럽게전미분을 생각하는 것입니다.
예를들어, df 라는 전미분은 어떤 점 p를 고정했을 때, p에서 주어진 방향으로 함수 f가 얼마나 '미소적으로' 변하는가를 나타내는 척도입니다. 구체적으로, 벡터 X = (X1, …, Xn)이 주어졌을 때, X 방향으로의 df의 값은
으로 정의됩니다.[1]물론, 여기서 (x1, …, xn)은 p점 근처에서의 좌표계입니다. 왜 이런 정의가 먹히는가를 생각해봅시다. 공간상의 두 점 p와 p+Δp가아주 가까이, 구체적으로 dp만큼의 아주 작은 변위만큼 떨어져 있다고 합시다. 이때 p와 p+Δp의 좌표를 각각x와 x+Δx로 적기로 하고,p에서 p+dp로 갈 때의 함수 f의 값의 변화량을 알기 위해 f를 p점 근처에서 테일러 전개해봅시다. 그러면
로 주어집니다. 따라서 극한적으로 2차항 이후를 무시하면
가 성립하며, 이로부터 df는 진실로 f의 함수값의 차이를 좌표계와 무관한 방식으로 재는 양임을 알 수 있습니다. 그러므로 위의 논의가 df의 정의를 정당화합니다.
가 되어 최종적으로 다음과 같은 오일러-라그랑주 방정식을 얻게 되며 두 라그랑지언에 의해 얻게 되는 운동방정식은 같게 된다.
일반적으로, 라그랑지언이 어떤 임의의 함수의 전미분만큼 달라도 같은 오일러-라그랑주 방정식을 얻는다.
오일러 - 라그랑지 방정식의 유도과정은 아래와 같다.
Euler-Lagrange Equation
It is a well-known fact, first enunciated by Archimedes, that the shortest distance between two points in a plane is a straight-line. However, suppose that we wish to demonstrate this result from first principles. Let us consider the length, , of various curves, , which run between two fixed points, and , in a plane, as illustrated in Figure 127. Now, takes the form
where . Note that is a function of the function . In mathematics, a function of a function is termed a functional.
Figure 127:Different paths between points and.
Now, in order to find the shortest path between points and , we need to minimize the functional with respect to small variations in the function , subject to the constraint that the end points, and , remain fixed. In other words, we need to solve
The meaning of the above equation is that if , where is small, then the first-order variation in , denoted , vanishes. In other words, . The particular function for which obviously yields an extremum of (i.e., either a maximum or a minimum). Hopefully, in the case under consideration, it yields a minimum of .
Consider a general functional of the form
where the end points of the integration are fixed. Suppose that . The first-order variation in is written
where . Setting to zero, we obtain
This equation must be satisfied for all possible small perturbations .
Integrating the second term in the integrand of the above equation by parts, we get
Now, if the end points are fixed then at and . Hence, the last term on the left-hand side of the above equation is zero. Thus, we obtain
The above equation must be satisfied for all small perturbations . The only way in which this is possible is for the expression enclosed in square brackets in the integral to be zero. Hence, the functional attains an extremum value whenever
This condition is known as the Euler-Lagrange equation.
Let us consider some special cases. Suppose that does not explicitly depend on . It follows that . Hence, the Euler-Lagrange equation (1681) simplifies to
Next, suppose that does not depend explicitly on . Multiplying Equation (1681) by , we obtain
However,
Thus, we get
Now, if is not an explicit function of then the right-hand side of the above equation is the total derivative of , namely . Hence, we obtain
which yields
Returning to the case under consideration, we have , according to Equation (1674) and (1676). Hence, is not an explicit function of , so Equation (1682) yields
where is a constant. So,
Of course, is the equation of a straight-line. Thus, the shortest distance between two fixed points in a plane is indeed a straight-line.
파란색의 점들이 각각의 샘플들이라면, 이들의 경향성을 따라서 직선을 그은것이 바로 위에서 설명한 LMS 수식으로 표현것입니다. 즉, 아주 간단한 근사화 방법으로써 실제로 많이 쓰이지만 그렇게 정확도가 높지는 않습니다.
이러한 데이터 혹은 샘플 혹은 어떠한 분포도를 하나의 수식으로 표현하기 위해서, 이를 모델화 한다고 합니다. 모델은 우리가 원하는 물리적인 현상을 잘 반영해야 합니다. 하지만 분명 오차가 발생하기 때문에, 이를 최소자승법을 통하여 원하는 결과값이 나오도록 하는 오류를 최소화 하는 변수값을 알아내는것이 핵심입니다.
이를 식으로 다시 이야기 해보겠습니다.
참조 : The Method of Least Squares of Steven J. Miller∗




































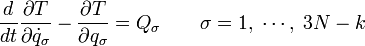
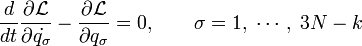
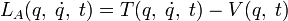 와 다음과 같은 좌표와 시간만의 임의의 함수
와 다음과 같은 좌표와 시간만의 임의의 함수 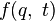 의 시간에 대한
의 시간에 대한 

 만큼 차이가 난다. 하지만 이는 상수이므로 여기에
만큼 차이가 난다. 하지만 이는 상수이므로 여기에 ![\delta S_B = \delta S_A + \delta \left[ \left. f(q,\; t) \right|_{t=t_2} - \left. f(q,\; t)\right|_{t=t_1} \right] = \delta S_A](http://upload.wikimedia.org/math/2/f/4/2f488153a43acf2179364e03da4e8046.png)