In probability theory and statistics, a sequence or other collection of random variables is independent and identically distributed (i.i.d.) if each random variable has the same probability distribution as the others and all are mutually independent.[1]
The abbreviation i.i.d. is particularly common in statistics (often as iid, sometimes written IID), where observations in a sample are often assumed to be effectively i.i.d. for the purposes of statistical inference. The assumption (or requirement) that observations be i.i.d. tends to simplify the underlying mathematics of many statistical methods (see mathematical statistics and statistical theory). However, in practical applications of statistical modeling the assumption may or may not be realistic. To test how realistic the assumption is on a given data set, the autocorrelation can be computed, lag plots drawn or turning point test performed.[2] The generalization of exchangeable random variables is often sufficient and more easily met.
The assumption is important in the classical form of the central limit theorem, which states that the probability distribution of the sum (or average) of i.i.d. variables with finite variance approaches a normal distribution.
Note that IID refers to sequences of random variables. "Independent and identically distributed" implies an element in the sequence is independent of the random variables that came before it. In this way, an IID sequence is different from a Markov sequence, where the probability distribution for the nth random variable is a function of the previous random variable in the sequence (for a first order Markov sequence). An IID sequence does not imply the probabilities for all elements of the sample space or event space must be the same.[3] For example, repeated throws of loaded dice will produce a sequence that is IID, despite the outcomes being biased.
줄여서 i.i.d.는 어떠한 랜덤 확률변수의 집합이 있을때 각각의 랜덤 확률변수들은 독립적이면서 (자기 사건의 발생의 영향이 다른 랜덤 확률변수에게 미치지 않을 때) 동일한 분포를 가질때를 의미한다.
예를들어서, 이항확률 분포 (성공 or 실패)를 가지는 동전던지기를 3회 실시한다고 가정하자.
각각의 시행은 이전이나 이후의 시행에 영향을 주지않는 독립시행이며 각각의 시행에서 나오는 동전의 앞,뒤에 대한 결과값의 분포는 동일한 이항확률 분포를 따르기 때문에 이는 i.i.d.라고 할수 있다.

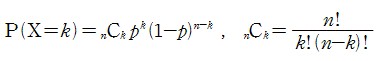
만약 이를 코드화나 모델링화 시킨다면, 변수의 값을 선택할 때 정의된 동일한 확률분포에서 표본을 선택한다면 이를 i.i.d.한 확률 표본이 된다고 할수가 있다.
[출처] 확률변수의 결합 - 확률표본|작성자 isabella
'N.&C. > Probability' 카테고리의 다른 글
| Sigma Notation (Summation Notation) and Pi Notatio (0) | 2016.10.11 |
|---|---|
| [Probability] Renewal theory : 추계적 과정 (0) | 2014.11.03 |
| [Markov Chain] You_tube Tutorial video. (0) | 2014.10.06 |
| [E-book] Poisson process (0) | 2014.10.06 |
| Markov chain [마코프 체인] (6) | 2013.05.09 |