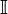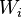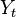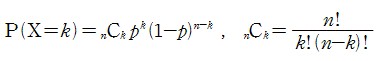Citation: http://users.jyu.fi/~timoh/TIES327/WPLS.pdf
*This contents refer to Dr. Zheng Chang's slidels. It does not utilize commercial uses. Thanks. *
Fundamentals of Physical Layer Security
최근 물리계층보안이라는 "Physical Layer Security (PLS)" 에 대한 연구가 관심을 많이 받고 있다. (이하 PLS로 부르겠다.)
이는 컴퓨터 네트워킹에서 주로 다루는 Open System Interconnect (OSI) model에서의 최하위 계층인 물리계층(PHY)(에서의 보안 달성을 연구하는 분야이다. 우리는 물리보안이라는 명명에서 흔한 인식의 오류를 접하는데, PLS는 Physical Layer네트워크에서 하드웨어 차원에서의 보안을 의미하는 것이 아니다. 오히려 통신이론과 같은 학문적인 분야에서의 PHY에서 다루는 다양한 기법들에 대한 해석과 고찰을 통하여 새로운 인식의 차원에서 보안을 달성하는 것이다.
PHY contains
–Definition of Hardware Specifications –Encoding and Signaling
–Data Transmission and Reception –Topology and Physical Network Design
ex) 핵심 기술들은 CDMA, OFDM, MIMO 등이 있다..
과거의 통신시스템에서 보안은 High Layer에서의 authentication, confidentiality, privacy 에 대한 이슈로 공개키나 비밀키, 암호화 기법 향상과 같은 방법으로 주로 발전해왔다. 하지만 지금은 정보이론과 신호처리, 암호학의 발전도가 높아짐에 따라 보안 시스템을 디자인 할때부터 물리계층의 불안전성에 대한 고려를 해야한다고 주장되고 있다. 예를 들면, Noise와 Fading은 Wireless Communications 에 있어서 하나의 장애요소로 보아왔지만, 정보이론의 관점에서 이들을 이용하여 Messages 를 잠재적인 도청자나 비인가 노드로부터 추가적인 보안키없이 숨길 수 있다고 제안되고 있다. 만약 위와 같은 방법으로 통신 Data Rate의 큰 희생없이 Cost-efficient way으로 PHY계층에서 보안을 달성할수 있다면 이는 PLS에 있어서 매우 의미있는 솔루션이 될 수 있다.
앞서 설명한 예가 PLS에 대한 기본 예시가 되겠지만, 명확한 이해를 위해서 아래의 컨셉도를 살펴보자.

3개의 터미널이 존재하며, 왼쪽에서부터 송신노드 T1, 적법한 수신노드 T2, 도청자 T3 이다. 만약 T2와 T3 노드간의 채널이 T1에서 전송한 신호가 Fading이나 Path-loss 를 겪는 이유로 서로 채널상태가 다르다면, 그리고 T3의 채널만 심각한 성능저하를 겪는다면? 이를 통하여 도청노드 T3은 T1 노드가 송신하고자 하는 본래의 신호를 수신 및 복원할 수 가 없게 되고, 이를 통하여 우리는 보안을 달성할 수 있게 된다. 아래의 그림은 PLS에서 주로 사용되는 기본적인 도청채널모델을 보여준다.

그림. Wiretap Channel Model
따라서, PLS는 기존의 보안통신체계가 통신채널의 물리적인 실체를 고려하지 않았던 점을 고려함으로써, 통신장애요소로써 제거와 회피에만 신경을 쓴 Noise나 Fading 요소를 보안달성을 위한 긍정적인 요소로 이용한다. 따라서, PLS는 더욱 더 실질적인 통신 모델인 Wiretap channel model을 사용하여 (Main channel 과 Eavesdropper’s channel 를 구분하는 모델) 보안달성을 위한 솔루션을 연구한다. (PLS 컨셉에 대한 핵심진술문장)

정보이론의 관점에서 위 그림은 Alice는 송신(TX)노드가 합적인 노드인 Bob에게 메세지 신호(M)을 전송하는 과정을 보여준다. 그림에서 Eve는 도청자로써 동일한 채널에서 송신 메세지를 수동적으로 도청하기만 한다. 본 모델에서, 공통적인 메세지인 M0는 Bob과 Eve모두에게 전달되지만 비밀메세지인 M1은 Bob에게만 전송된다. 이와 같이 PLS의 관점에서, 최대 목표는 비밀 메세지인 M1의 전송률 (Secrecy Capacity) 을 Maximize 하는 것이다.
(가정사항)
1.Z should provide no information about M1
2.Y can be decoded into M with negligibly small probability of error

아래의 수식은 위와 같은 시나리오, 가우시안 도청 채널 모델에서의 보안용량 수식을 보여준다.
Secrecy Capacity of Gaussian Wiretap Channel :

지금까지 PLS에 대한 연구는 다양한 방법으로 시도 되고 있는데, 아래와 같이 몇가지로 분류 할수가 있다.
– Preprocessing Scheme
• Coding
• Key generation
• Artificial Noise Scheme
– Game Theoretic Scheme
– Signal Processing
– Cooperation Communications




![0 < \mathbb{E}[S_i] < \infty.](http://upload.wikimedia.org/math/6/4/2/642646acd87e01cd6befabcb8ba03731.png)
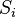

![\mathbb{E}[S_i]](http://upload.wikimedia.org/math/9/2/e/92e2d7bbd26c3eb3dfb9666dad1b61a3.png)
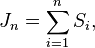


![[J_n,J_{n+1}]](http://upload.wikimedia.org/math/6/b/e/6bec9ae0b54f0d735f3511a0aa7f0507.png)